게임 데이터 실시간 처리를 위해 Kafka의 구조와 개발 방법을 익히기 위해 팀원과 스터디를 진행하기로해 앞으로 블로그에 책의 내용을 정리 요약하여 발표할 계획이다. 우선 1장에서 카프카에 간단한 소개와 2장에서는 카프카 설치에 관한 내용으로 간단히 진행해 보기로한다.
1.1 카프카의 탄생 배경
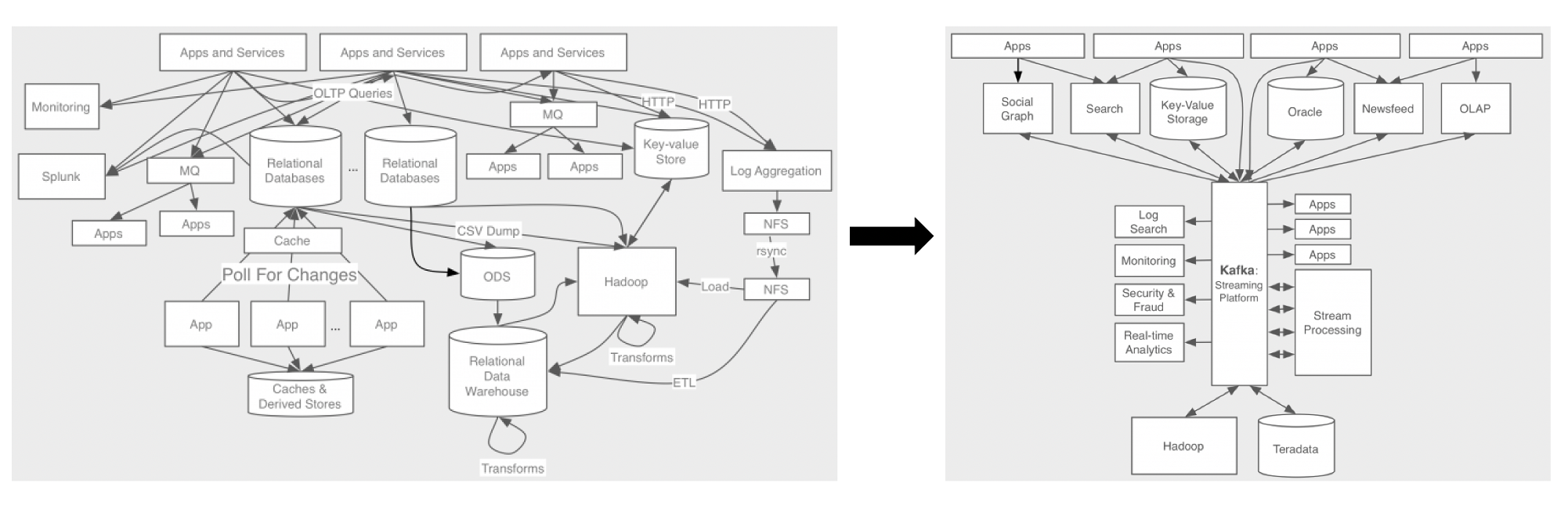
카프카의 탄생 배경은 위의 그림으로 잘 설명이 가능할거같은데 기본적으로 서비스가 확장에 나감에 따라 데이터 파이프라인이 복잡해져 이를 한곳에 모아두고 전달할수 있는 메시지 전달 플랫폼을 만들었고 그것이 바로 카프카이다.
카프카는 다음과 같은 목표를 가지고 만들었다.
- 프로듀서와 컨슈머 분리 (데이터 생성자와 소비자 분리)
- 메시징 시스템과 같이 영구 메시지 데이터를 여러 컨슈머에게 허용
- 높은 처리량을 위한 메시지 최적화
- 데이터가 증가함에 따라 스케일아웃이 가능한 시스템.
1.2 카프카의 동작 방식과 원리
- 카프카의 동작 방식 : 카프카는 메시징 서버로 동작하는데 메시징 시스템이란 메시지라고 불리는 데이터를 생산하는 프로듀서와 소비하는 컨슈마가 있고 이 컨슈머는 토픽을 구독하여 데이터를 가져간다.
- Pub/Sub 모델이란? : 카프카와 같이 중앙에 메시징 시스템을 두고 메시지를 보내고(Publish) 받는(Subscribe) 형태의 통신을 Pub/Sub 모델이라고 한다.
- Pub/Sub 모델의 장점 : 일반적인 통신 모델은 클라이언트간에 모두 연결이 되어있어야 해서 통신에 참여하는 개체가 많아지면 복잡하고 확장성이 좋지 않지만, Pub/Sub 모델 중간에 메시징 시스템이 있기 때문에 메시징 시스템만 살아있다면 전달되던 메시지가 사라지지않고 메시징 시스템 중심으로 연결되기 때문에 확장성이 좋다.
- Pub/Sub 모델의 단점 : 중간에 있는 메시징 시스템이 메시지를 관리하기 떄문에 대용량 데이터를 전달하기에는 적합하지 않다.
- 카프카가 Pub/Sub모델의 단점을 극복한 이유 :카프카는 프로슈머와 컨슈머가 직접 메시지 교환 전달의 신뢰성 관리를 하게 하고 부하가 많이 걸리는 교환기 기능도 직접하지 않아 메시징 전달에만 집중할 수 있어 성능 향상을 꾀하였다 또한 카프카 역시 비동기 시스템으로 컨슈머는 프로슈머와 관계없이 데이터를 가져가고 프로슈머또한 컨슈머와 관계없이 데이터를 생산한다.
1.3 카프카의 특징
- 프로듀서와 컨슈머의 분리 : 프로슈머와 컨슈머를 분리하여 어느 한쪽에 시스템에서 문제가 발생해도 연쇄 작용이 일어날 확률을 줄였다.
- 멀티 프로듀서 멀티 컨슈머 : 카프카는 하나의 토픽에 여러 프로듀서 또는 컨슈머들이 접근이 가능하게 해 각각의 서버에 데이터를 전달하지 않아도 카프카를 통해서 데이터를 이동시킬 수 있기 때문에 중앙 집중현 구조를 만들 수 있다.
- 디스크에 메시지 저장 : 기존의 메시징 시스템과 가장 큰 다른점 중 하나는 디스크에 메시지를 저장하는건데 이렇게 함으로써 트래픽이 일시적으로 폭증해 컨슈머의 처리가 늦어져도 데이터를 유실하지않고 작업이 가능하다.
- 확장성이 종다.
- 높은 성능
1.4 카프카의 확장과 발전
카프카를 통해 고성능 Pub/Sub 모델로 기업은 SOA(Service Oriented Architecture)의 핵심 요소중 하나인 ESB(Enterprise Service Bus)를 쉽게 구현 할 수 있게 되었다. SOA는 업무를 서비스 단위로 쪼개고 각 서비스간의 연결은 ESB를 통해 연결한다는 철학을 지향한다. ESB의 특징은 아래와 같다.
- 다양한 시스템과 연동하기 위한 멀티 프로토콜과 데이터 타입 지원
- 느슨한 결합을 위한 메시지 큐 지원
- 이벤트 기반 통신 지향
2.0 카프카의 간단한 구성도
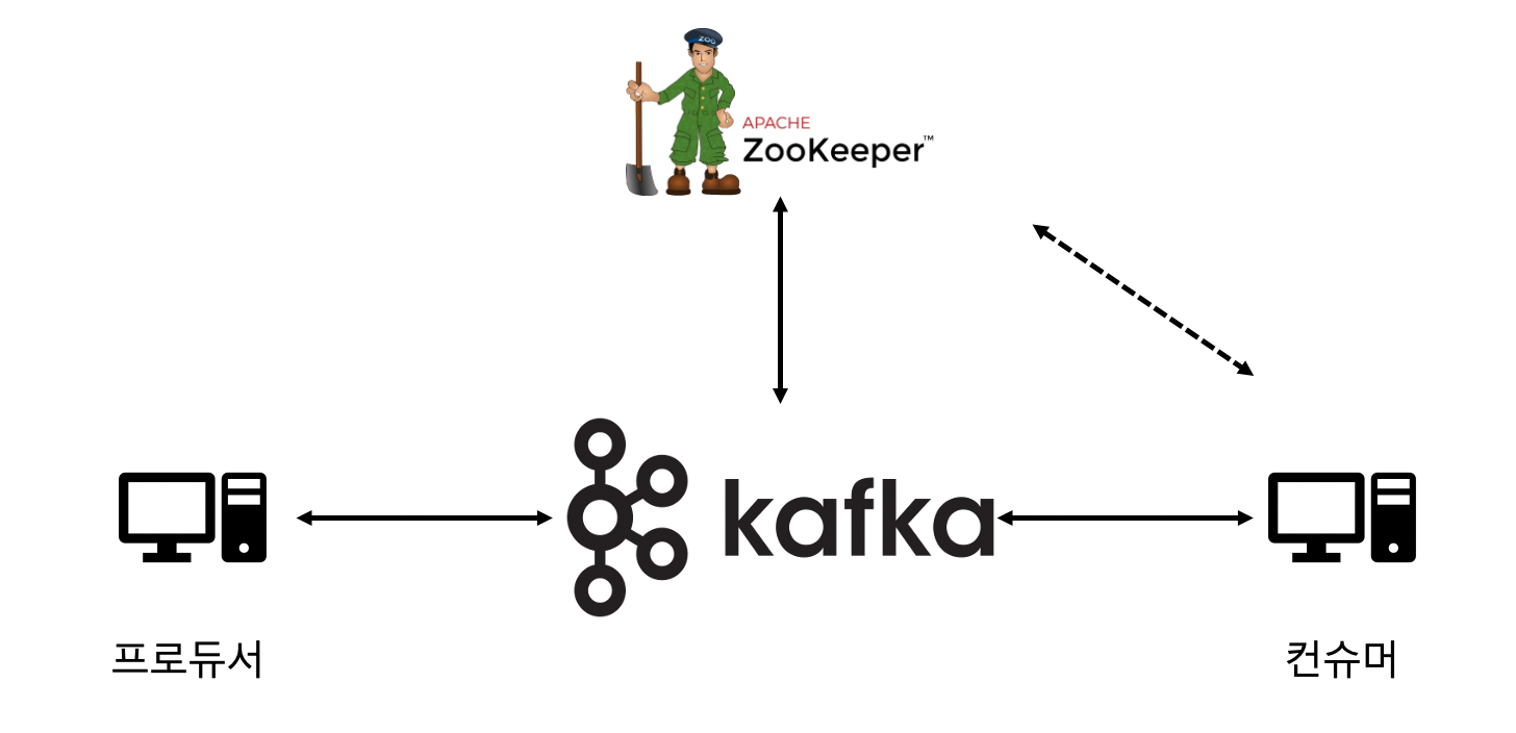
위의 그림처럼 Kafka는 Apache Zookeeper를 코디네이션 어플리케이션으로 사용하는데 Kafka를 설치하기전 Zookeeper에대해 간단히 알아보고 시작한다.
2.1 카프카 관리를 위한 주키퍼
주키퍼는 본래 하둡의 서브 프로젝트중 하나였지만, 2011년 1월 부터 아파치 탑 레벨 프로젝트로 승격되었고 현재는 Kafka뿐만 아니라 Storm, Hbase, NiFi등 많은 어플리케이션에서 사용중이다.
주키퍼는 분산 어플리케이션을 위한 코디네이션 시스템으로 분산되어 있는 각 어플리케이션의 정보를 중앙에 집중하고 구성 관리, 그룹 관리 네이밍, 동기화 등의 서비스를 제공한다.
하둡에서 주키퍼는 노드들의 상태를 관리하고 Active 네임노드가 죽으면 Stanby 네임노드를 Active로 바꿔주는 HA 구성에도 필요하다.
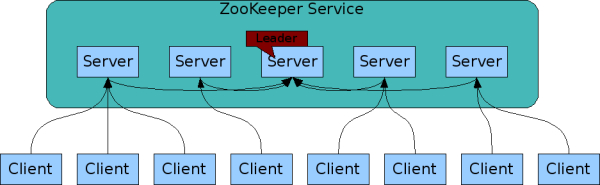
위의 그림처럼 주키퍼는 서버 여러대를 클러스터로 구성하고 분산 어플리케이션들이 각각 클라이언트가 되어 주키퍼 서버들과 커넥션을 맺어 상태 정보등을 주고 받는다. 이때 상태 정보들은 주키퍼의 znode에 키 밸류 형태로 저장되고 znode에 키값이 저장된것을 이용하여 분산 어플리케이션들이 서로의 데이터를 주고 받게 된다. 주키퍼에서 사용되는 znode는 데이터를 저장하기 위한 공간으로 일반 컴퓨터의 파일이나 폴더 개념이라고 생각하면 된다.
일반적으로 znode에 저장되는 데이터 크기는 바이트에서 킬로바이트로 매우 작지만 모든 데이터는 메모리에 저장하기 떄문에 jvm의 heap memory를 모든 znode를 올릴 수 있는 충분한 크기로 만들어야 한다.
또한 아래 그림 처럼 디렉토리와 비슷한 구조로 자식노드를 가지고있는 계층형 구조로 되어있다.
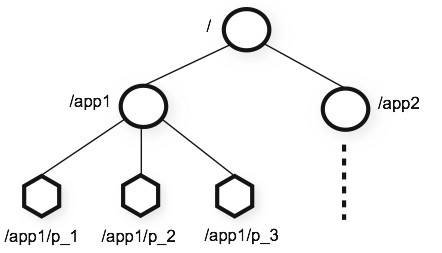
주키퍼의 지노드는 데이터 변경 등에 대한 유효성 검사를 위해 버전 번호를 관리하며 데이터가 변경될 때마다 지노드의 버전 번호가 증가하게 된다. 앙상블(클러스터)로 구성되어 있는 주키퍼는 노드가 과반수 이상 유지된다면 지속적인 서비스가 가능하다. 이 내용을 보면 주키퍼는 홀수로 구성하는게 효율이 좋을것으로 예상된다.
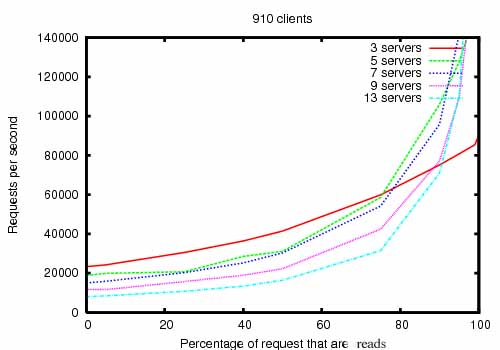
또한 아래 그래프를 보면 노드수에 비해 꾀나 선형적으로 데이터 처리량이 증가하는것을 보인다.
2.2 주키퍼 설치
나는 VM을 새로 만들기보다 Docker에 centos 7.4 기본 이미지가 있기 때문에 my-net이라는 네트워크를 만들고 khg-zk001~khg-zk003 컨테이너를 만들어 설치를 하려고한다. 아래 처럼 –privileged 옵션과 /sbin/init으로 실행시킨 후 docker exec -it {컨테이너명} /bin/bash로 들어가야 systemd reload가 가능하다.
1번서버 : docker run --privileged -dit -h khg-zk001 --network my-net --name khg-zk001 -v $PWD/zk003/opt:/opt -v $PWD/zk001/data:/data centos7-base:7.4 /sbin/init
2번서버 : docker run --privileged -dit -h khg-zk002 --network my-net --name khg-zk002 -v $PWD/zk003/opt:/opt -v $PWD/zk002/data:/data centos7-base:7.4 /sbin/init
3번서버 : docker run --privileged -dit -h khg-zk003 --network my-net --name khg-zk003 -v $PWD/zk003/opt:/opt -v $PWD/zk003/data:/data centos7-base:7.4 /sbin/init
책에서는 사전 준비로 openjdk를 설치하기 떄문에 각 컨테이너에서 아래 명령어로 openjdk를 설치했다.
yum -y install java-1.8.0-openjdk
2.2.1 주키퍼 다운로드
책은 2018년에 출간되어서 그런지 주키퍼 3.4.10 버전을 설치했다. 현재는 3.7.0 버전까지 릴리즈되었지만 원활한 실습 진행을 위해 책과같은 3.4.10 버전을 설치하도록 하겠다. 컨테이너에는 wget도 설치되어있지 않아 아래 명령어로 설치하였다.
yum -y install wget
아래 명령어로 주키퍼 다운로드 (현재 공식홈페이지 링크는 책이랑 링크가 좀다르다.)
wget https://archive.apache.org/dist/zookeeper/zookeeper-3.4.10/zookeeper-3.4.10.tar.gz
아래 명령어로 압축 해제
tar zxf zookeeper-3.4.10.tar.gz
아래 명령어로 zookeeper-3.4.10 디렉토리에 zookeeper라는 이름의 심볼릭 링크 설정
ln -s zookeeper-3.4.10 zookeeper
주키퍼는 어플리케이션에서 별도의 데이터 디렉토리를 사용하는데 이 디렉토리에는 앞서 2장에서 말한 znode의 복사본인 스냅샷과 트랜잭션 로그들이 저장되며 지노드에 변경사항이 발생되면 이 data 디렉토리에 트랜잭션 로그에 변경사항이 추가된다.
이 로그가 어느정도 커지면 현재 모든 노드의 스냅샷이 파일 시스템에 저장되는데 이 스냅샷은 이전의 로그들을 대체하게된다.
한마디로 data디렉토리에 모든 로그가 저장되고 저장된 로그가 커지면 해당 시점에 스냅샷이 저장되는 디렉토리로 zookeeper가 분산 코디네이션을 수행하는데 중요한 디렉토리이다.
나는 책과 같이 /data 경로에 디렉토리를 생성했다.
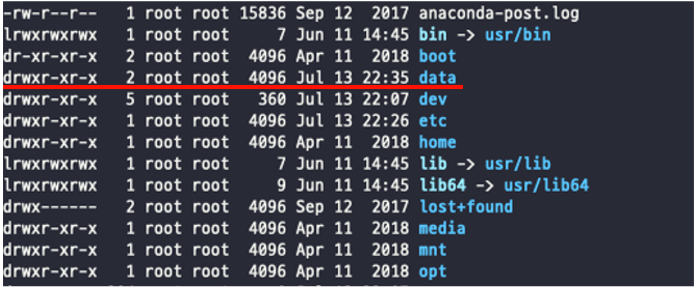
다음 단계로 앙상블(클러스터) 내 주키퍼 노드를 구분하기 위해 ID를 만들어야하는데 이를 주키퍼에서는 myid라고 부르며 정수 형태로 만들어주면 된다.
echo 1 > /data/myid
다른 서버에도 아이디를 2,3으로 생성한다.
다음으로는 주키퍼 환결성정을 만들어야하는데 나는 주키퍼를 /opt 디렉토리 밑에 압축을 풀었기 때문에 아래 명령어로 zoo.cfg 파일을 생성한다.
vi /opt/zookeeper/conf/zoo.cfg
책에서는 아래의 환경설정을 작성하라고 나와있는데 conf디렉토리에 zoo_sample.cfg라는 파일이있어 복사 붙혀넣기하면 빠르게 작성할수 있다.
# The number of milliseconds of each tick
# 주키퍼가 사용하는 시간에 대한 기본 측정 단위(밀리초)
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take : 팔로워가 리더와 초기에 연결하는 시간에 대한 타임 아웃 tick의 수
# 이 설정에서는 기본 tickTime이 2000밀리세컨드이기 때문에 20000밀리세컨드 안에는 연결을해야 타임아웃이 안나게 된다.
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
# 팔러워가 리더와 동기화 하는 시간에 대한 타임 아웃 tick의 수(주키퍼의 데이터가 크면 늘려야한다.)
# 이 설정에서는 5*2000(tickTime)안에 동기화를 못하면 앙상블에서 해당 서버는 제외가 된다.
syncLimit=5
# the directory where the snapshot is stored.
# 트랜잭션 로그와 스냅샷이 저장되는 경로
dataDir=/data
# the port at which the clients will connect
# 주키퍼 사용 TCP 포트
clientPort=2181
# server.{myid} 형식으로 주키퍼 앙상블을 구성하기 위한 서버의 정보를 설정.
# 2388,3888은 기본 설정으로 앙상블 노드간 연결하는데 사용되며 리더 선출에 사용된다.
server.1=khg-zk001:2888:3888
server.2=khg-zk002:2888:3888
server.3=khg-zk003:2888:3888
2.2.2 주키퍼 실행
아래의 명령어로 주키퍼 실행과 종료가 가능하다.
주키퍼 실행 : /opt/zookeeper/bin/zkServer.sh start
주키퍼 종료 : /opt/zookeeper/bin/zkServer.sh stop
이제 다음으로는 systemed에 주키퍼 프로세스를 등록시킬건데 여기서 systemed란 부팅 중 시작하는 서비스, 데몬들을 관리하는 시스템으로 여기에 추가하게 되면 서버 부팅시 바로 주키퍼를 실행시킬 수 있다. systemed에 등록하기 위해서는 주키퍼용 systemed라는 파일을 만드는데 이 책에서는 zookeeper-server.service라는 명칭으로 만든다.
vi /etc/systemd/system/zookeeper-server.service
zookeeper-server.service 파일에 아래와 같이 작성한다. 책과는 설치경로가 다른것 외에는 동일하다.
# Unit은 일반적인 옵션을 나타내며 가장 많이 사용되는 옵션은 After 또는 Before인데 옵션명 그대로 부팅시 시작되는 어떤 유닛이 시작되기 전이나 시작후에 해당 서비스를 실행시키겠다는 내용이다.
# 유닛의 종류는 https://haker.tistory.com/51에 잘정리가 되어있으니 나중에 한번 보는것도 좋겠다.
[Unit]
Description=zookeeper-server
After=network.target
# Service옵션은 서비스 실행과 관련된 옵션으로 책에 아래와 같이 정리가 되어있다.
# Type : ExecStart에 영향을 주는 유닛 프로세스가 시작되며 simple, forking, oneshot, idle가 있다.
# SyslogIdentifier : syslog에서 구분하기 위한 이름.
# WorkingDirectory : 실행된 프로세스의 작업 디렉토리를 의미하며 만약 설정하지 않으면 사용자 계정의 홈으로 지정됨.
# Restart : 이 옵션을 always로 설정하면 systemctl 명령어로 중지한 경우를 제외하고는 항상 프로세스가 종료된 뒤 재시작.
# RestartSec : 이 옵션은 Restart옵션과 연결되어 몇 초에 실행할지를 결정.
# ExecStart,ExecStop : 서비스가 실행, 정지될 때 실행할 명령어 또는 스크립트 설정.
[Service]
Type=forking
User=root
Group=root
SyslogIdentifier=zookeeper-server
WorkingDirectory=/opt/zookeeper
Restart=always
RestartSec=0s
ExecStart=/opt/zookeeper/bin/zkServer.sh start
ExecStop=/opt/zookeeper/bin/zkServer.sh stop
systemed의 파일을 새로 만들거나 기존 파일을 수정한 이후에는 반드시 systemd 재시작을 위해 아래 명령어를 실행해야한다.
systemctl daemon-reload
다음으로는 주키퍼 서비스가 서버가 부팅될 때 자동으로 실행될 수 있도록 허용한다.
systemctl enable zookeeper-server.service
아래의 명령어로 주키퍼 서버 상태 확인.
systemctl status zookeeper-server.service

첫번째 줄의 zookeeper-server.service - zookeeper-server 는 systemd 옵션 중 Description으로 정의했던 부분이 출력.
두번째 줄의 Loaded: loaded (/etc/systemd/system/zookeeper-server.service; static; vendor preset: disabled) 은 해당 설정이 OS 메모리 영역에 로드 되었는지 확인할수 있는 부분으로 자동 시작으로 되어있으면 enable 이다.
Active: active (running)로 시작하는 세번째 줄은 해당 서비스가 잘 실행되고있는지 확인할 수 잇으며 실행된지 얼마나 지났는지도 알수있다.
Process 부분은 주키퍼 프로세스 관련 부분과 실행시 옵션 부분을 확인 할 수 있다.
날짜로 시작하는 영역은 주키퍼 관련 로그를 볼 수 있다.
2.3 카프카 설치
kafka는 과반수 이상이 장애가나도 1대 이상만 정상작동하면 서비스가 멈추진 않기 때문에 굳이 홀수로 구성해야할 필요는 없으며 주키퍼와는 다른 서버 구성을 추천한다.
2.3.1 카프카 다운로드
카프카도 주키퍼와 마찬가지로 자바를 설치 후 책에서는 1.0.0 버전을 설치하며 현재 작성일 기준으로는 2.8.0 버전 까지 릴리즈 된걸로보아 꾸준한 업데이트가 있는걸로 보인다. kafka는 스칼라 버전도 선택 가능한데 책에서 2.11 버전으로 설치하고있다. (kafka 내부에서 스칼라를 사용하는듯 하다.)
아래 명령어로 카프카를 다운로드 받는다.
wget https://archive.apache.org/dist/kafka/1.0.0/kafka_2.11-1.0.0.tgz
다음으로는 주키퍼와 마찬가지로 압축 해제후 링크를 걸도록한다.
tar xfz kafka_2.11-1.0.0.tgz
ln -s kafka_2.11-1.0.0 kafka
2.3.2 카프카 환경설정
카프카도 주키퍼와 마찬가지로 서버별 브로커 아이디, 카프카 저장 디렉토리, 주키퍼 정보를 작성해야한다. 또한 저장 디렉토리는 디스크가 분리되어있는 환경이라면 I/O를 분산시키기위해 각각의 디스크를 마운트시켜 하는편이 좋다. 하지만, 현재 실습 환경은 하나의 서버에서 도커로 진행하고있기 때문에 /data라는 디렉토리 하나만 생성시킨다. 디렉토리 생성 다음으로는 카프카가 바라보는 주키퍼의 정보를 결정하면되는데 아래의 그림과 같이 주키퍼 서버 정보를 1대만 입력할 경우의 시나리오다.
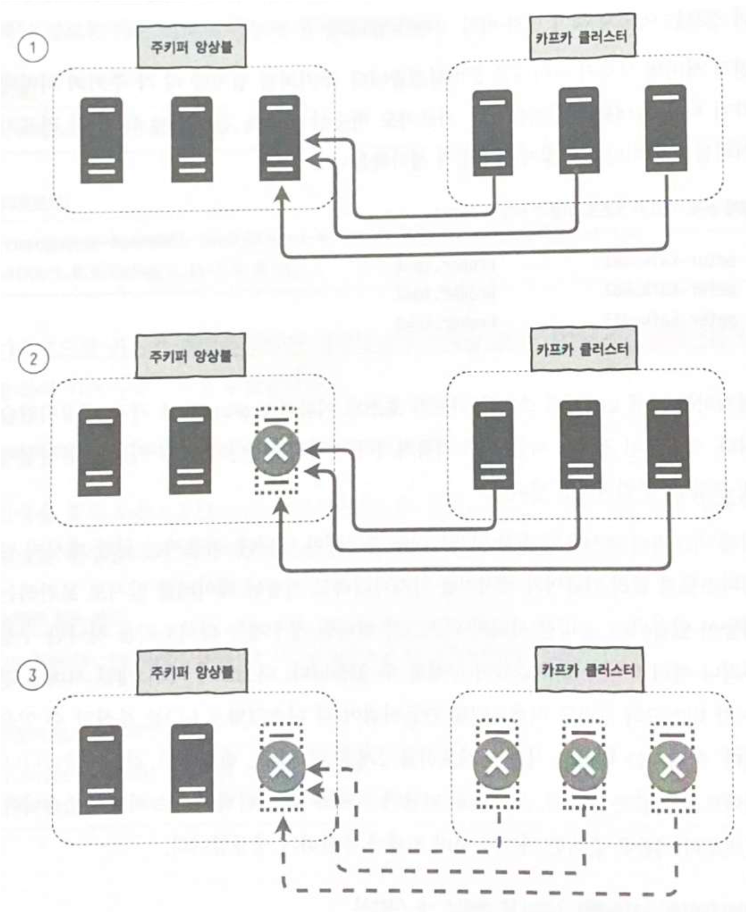
위의 그림 처럼 한대만 입력한다면 주키퍼가 다운되지 않아도 바라보는 서버가 장애가 발생한다면 카프카 서비스도 장애를 발생시키기 때문에 주키퍼 앙상블의 모든 서버 정보를 입력해야한다.
주키퍼 서버 정보를 입력할 때 아래와 같이 호스트 이름과 포트 정보만 입력하면 지노드의 최상위 경로만 사용하게 되는데 그 이유는 서로 다른 어플리케이션에서 동일한 지노드를 사용한다면 데이터 충돌 가능성이 있기 때문이다.
zookeeper.connect=khg-zk001:2181,khg-zk002:2181,khg-zk003:2181
하지만 아래와 같이 입력하면 주키퍼 앙상블 한 세트로 여러 개의 어플리케이션을 사용할 수있다.
1.
zookeeper.connect=khg-zk001:2181,khg-zk002:2181,khg-zk003:2181/khg-kafka01
zookeeper.connect=khg-zk001:2181,khg-zk002:2181,khg-zk003:2181/khg-kafka02
or
2.
zookeeper.connect=khg-zk001:2181,khg-zk002:2181,khg-zk003:2181/kafka/01
zookeeper.connect=khg-zk001:2181,khg-zk002:2181,khg-zk003:2181/kafka/02
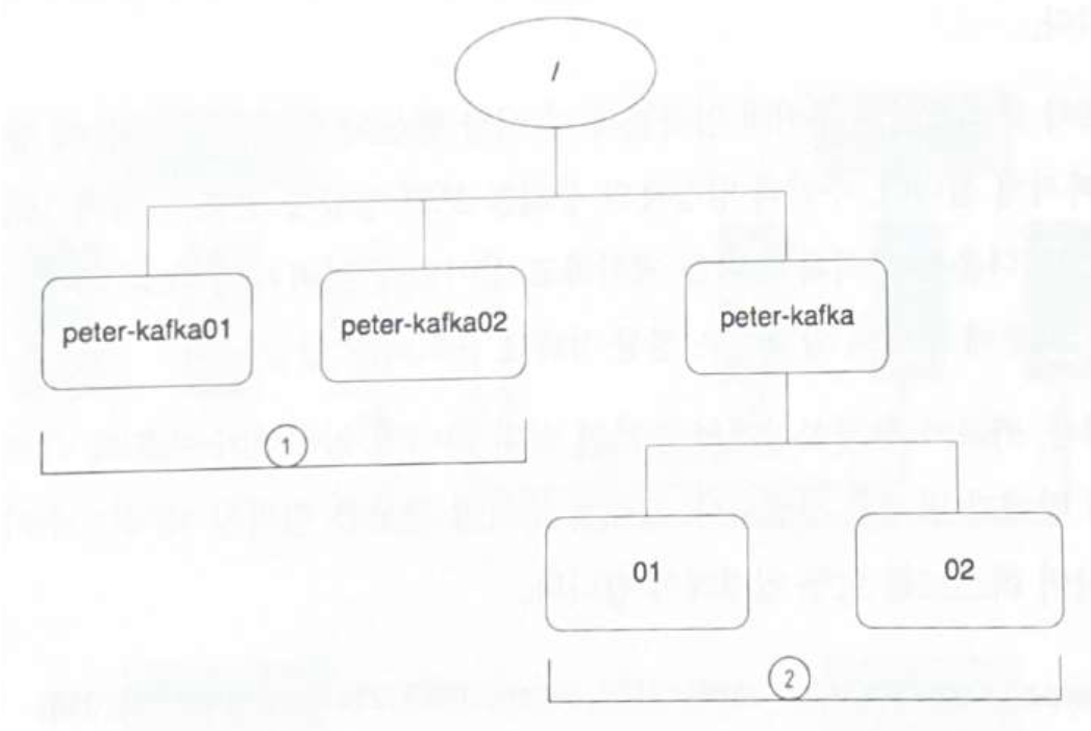
1번 처럼 작성하게 되면 지노드 루트 밑에 각각 서버명으로 지노드가 생성되고 2번 처럼 작성하면 루트 밑에 서비스명 밑에 지노드를 각각 생성 할 수 있다.
이제 vi로 kafka/config/server.properties파일을 수정해 아래와 같이 kafka 환경설정을 하도록 한다.
############################# Server Basics #############################
# The id of the broker. This must be set to a unique integer for each broker.
# 1번서버는 1 2번은 2 3번은 3
broker.id=1
############################# Log Basics #############################
# A comma seperated list of directories under which to store log files
log.dirs=/data
############################# Zookeeper #############################
# Zookeeper connection string (see zookeeper docs for details).
# This is a comma separated host:port pairs, each corresponding to a zk
# server. e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002".
# You can also append an optional chroot string to the urls to specify the
# root directory for all kafka znodes. /khg-kafka 아래 지노드를 지정안하면 알아서 만든다.
zookeeper.connect=khg-zk001:2181,khg-zk002:2181,khg-zk003:2181/khg-kafka
카프카 주요 옵션
| 옵션 | 설명 |
|---|---|
| broker.id | 브로커를 구분하기 위한 ID |
| delete.topic.enable | 토픽 삭제 기능을 on/off(enable = 토픽 삭제 기능)} |
| default.replication.factor | 리플리케이션 팩터(Replication Factor) 옵션을 주지 않았을 경우의 기본값 |
| min.insync.replicas | 최소 리플리케이션 팩터 |
| auto.create.topics.enable | 존재하지 않는 토픽으로 퍼블리셔가 메시지를 보냈을 때 자동으로 토픽생성 |
| offsets.topic.num.partitions | offsets 토픽의 파티션 수 |
| offsets.topic.replication.factor | 토픽의 최종 압축형태, gzip, snappy, lz4 등의 표준 압축 포맷 지원. uncompressed는 압축을 하지 않음. producer는 producer가 보내는 압축 형태를 유지하라는 옵션 |
| log.dirs | 로그 저장 위치 |
| num.partitions | 파티션 수 옵션을 주지 않았을 경우의 기본값 |
| log.retention.hours | 저장된 로그의 보관 주기 |
| log.segment.bytes | 저장되는 로그 파일 하나의 크기 |
| log.retention.check.interval.ms | 로그 보관주기 체크 시간 |
| message.max.bytes | 카프카에서 허용하는 가장 큰 메세지 크기 |
| zookeeper.connect | 주키퍼 접속정보 |
| zookeeper.session.timeout.ms | 주키퍼 연결 최대 대기 시간 |
| unclean.leader.election.enable | ISR 그룹에 포함되지 않은 마지막 리플리카를 리더로 인정. true(인정)/false(no 인정) |
| log.flush.interval.ms | 메시지가 디스크로 플러시되기 전 메모리에 유지하는 시간 |
| log.flush.interval.messages | 메시지가 디스크로 플러시되기 전 누적 메시지 수 |
옵션을 변경하면 반드시 카프카 클러스터를 재기동해야 변경된 옵션이 적용됨.
2.3.3 카프카 실행
카프카는 실행시 시작 명령어와 카프카 환경 설정파일을 옵션으로 주어 실행시킴.
포어그라운드 실행 : /opt/kafka/bin/kafka-server-start.sh /opt/kafka/config/server.properties
백그라운드 실행 : /opt/kafka/bin/kafka-server-start.sh /opt/kafka/config/server.properties &
systemd에 kafka-serer.service 작성.
[Unit]
Description=kafka-server
After=network.target
[Service]
Type=simple
User=root
Group=root
SyslogIdentifier=kafka-server
WorkingDirectory=/opt/kafka
Restart=no
RestartSec=0s
ExecStart=/opt/kafka/bin/kafka-server-start.sh /opt/kafka/config/server.properties
ExecStop=/opt/kafka/bin/kafka-server-stop.sh
이후 작업은 주키퍼와 마찬가지로 reload -> enable ->상태확인 순으로 진행.
2.4 카프카 상태 확인
2.4.1 TCP 포트 확인
주키퍼의 기본 포트는 2181/카프카의 기본 포트는 9092로 netstat -ntlp | grep {port}로 포트가 리슨 중인지 확인.
2.4.2 주키퍼 지노드를 이용한 카프카 정보 확인
주키퍼 CLI를 통해 카프카 지노드가 생성되어있는지 확인. 주키퍼 CLI는 zookeeper설치경로 밑에 bin/zkCli.sh 를 실행하면 된다 나의 경우 아래와 같이 PATH와 alias 잡아두어서 zkCli만 입력하면 CLI 실행이 가능하다.
# .bash_profile
# Get the aliases and functions
if [ -f ~/.bashrc ]; then
. ~/.bashrc
fi
# User specific environment and startup programs
ZOOKEEPER_HOME=/opt/zookeeper
PATH=$PATH:$HOME/bin
export PATH
alias zkCli='$ZOOKEEPER_HOME/bin/zkCli.sh'
zkCli 실행후 내가 설정한 khg-kafka 지노드가 생성되어있는지 확인한다.
2.4.3 카프카 로그 확인
카프카 홈디렉토리 밑 logs디렉토리에 있는 server.log에서 로그확인이 가능하다.
2.5 카프카 시작하기
아래의 명령어를 통해 토픽을 생성해보자.
/opt/kafka/bin/kafka-topics.sh \
--zookeeper khg-zk001:2181,khg-zk002:2181,khg-zk003:2181/khg-kafka \
--replication-factor 1 --partitions 1 --topic khg-topic --create

토픽을 잘못 생성한 경우 삭제도 가능한데 이경우 delete의경우 delete.topic.enable=true로 설정되어있어야 delete가 가능하다. 기본적으로 아무 설정하지 않았는데 delete가 되는걸로봐선 default값이 true인듯하다.
delete 명령어.
/opt/kafka/bin/kafka-topics.sh \
--zookeeper khg-zk001:2181,khg-zk002:2181,khg-zk003:2181/khg-kafka \
--topic khg-topic --delete
다음으로는 만들어진 토픽을 이용해 kafka-console-producer.sh를 통해메시지를 퍼블리싱하는 명령어이다.
/opt/kafka/bin/kafka-console-producer.sh \
--broker-list khg-kafka001:9092,khg-kafka002:9092,khg-kafka003:9092 \
--topic khg-topic
위의 명령어를 실행하면 프롬프트 창이 나오는데 거기에 This is a message와 This is another message를 입력후 Ctr+c 버튼으로 빠져나간다. 이렇게 입력된 메시지를 가져오는것은 kafka-console-consumer.sh를 이용하여 가능하다.
/opt/kafka/bin/kafka-console-consumer.sh \
--bootstrap-server khg-kafka001:9092,khg-kafka002:9092,khg-kafka003:9092 \
--topic khg-topic --from-beginning
나의 경우 아래와 같이 1번서버에서 메시지를 만든후 2번서버에서 메시지 생성을 확인했다.

