이번 글은 빅데이터를 지탱하는 기술이라는 책을 읽고 공부한 내용을 정리한 내용이다.
이 책에서는 대용량 데이터를 빠르게 집계하는 방법으로 압축과 분산의 방식으로 데이터를 처리하는 방법을 소개한다.
여기서 압축은 컬럼지향 데이터베이스로 컬럼을 압축하여 데이터를 저장하는 데이터베이스를 소개하며 분산은 MPP(Massive Parallel Processing) 데이터베이스를 소개한다.
1. 컬럼지향 데이터베이스란?
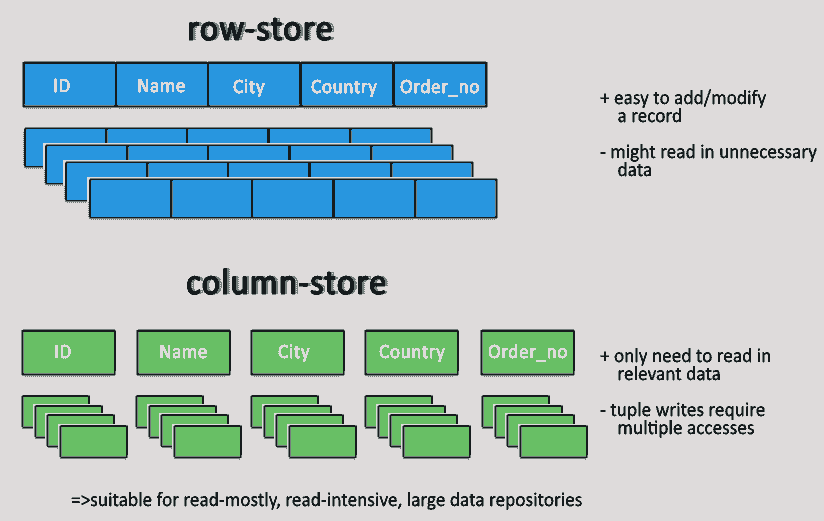
일반적으로 우리가 잘 알고 쓰고 있는 RDB(Oracle, MySQL)은 모두 행 지향 데이터베이스로 디스크에 레코드단위로 데이터를 읽고 쓴다.
그렇기 때문에 Select 절에 특정 컬럼만 넣는다고 해서 그 컬럼만 읽는 것이 아니다.
하지만 컬럼지향 데이터베이스는 디스크에 컬럼단위로 데이터를 읽고 쓰기 때문에 우리가 Select 절에 넣은 컬럼만 조회를 할 수 있다.
또한 이렇게 저장하게 되면 압축 효율도 높아지는데 PK가 아닌 이상 같은 컬럼에 종종 유사한 데이터가 나열되기 때문에 압축에 효율적이다.
이러한 압축효율과 원하는 컬럼만 선택하요 DISK I/O를 발생시키기 때문에 DW를 모델링할 때 테이블에 컬럼을 많이 만들어 사용할 수 있다는 장점이 있다.
하지만 데이터가 컬럼별로 저장되어있기 때문에 특정 로우의 데이터를 업데이트시킬 때 성능은 떨어지며 삽입 속도는 더 느리다.
그렇기에 업데이트와 삽입이 빈번한 DB에는 적합하지 않다고 생각한다.
아래 그림은 컬럼지향과 열지향 데이터베이스의 차이를 도식화해놓은 그림이다.
출처 : https://mkhernandez.wordpress.com/2019/01/19/column-oriented-nosql-databases/
2. MPP 데이터베이스란?
MPP 데이터베이스는 Massive Parallel Processing의 약자로 대규모 병렬 프로세스 데이터베이스이다.
즉 MPP 데이터베이스는 하나의 쿼리를 여러개의 프로세스로 병렬처리하는 데이터베이스이다.
그렇기에 MPP 데이터베이스는 기본적으로 컬럼지향 데이터베이스로 설계되어있다 그 이유는 대용량 데이터를 집계할 때 컬럼들이 여러 Disk에 저장되어있어야 많은 프로세스들이 개별 Disk에 접근하여 데이터를 처리할 수 있기 때문이다.
이러한 특징으로 MPP 데이터베이스는 대용량 데이터 집계에 최적화된 데이터베이스로 대규모의 DW를 구축할 때 사용하면 좋은 데이터베이스이다.
MPP 데이터베이스의 특징으로는 테이블을 생성할 때 데이터를 어떻게 분산하여 저장할 것인지 선택을 해야 만들 수 있다.
AzureDW를 사용했을 때 Hash, RoundRobin 방식을 선택하여 테이블을 만들었다.
아래 그림은 Azure DW의 MPP 데이터베이스의 아키텍처이다.

출처 : https://medium.com/@putrasulung2108/mpp-architecture-6bfb11b27a6a