이번글에서는 Hive에서 작성된 SQL이 어떠한 과정을 통해 M/R, Tez, Spark로 작업이 처리되는지 알아보려고 한다.
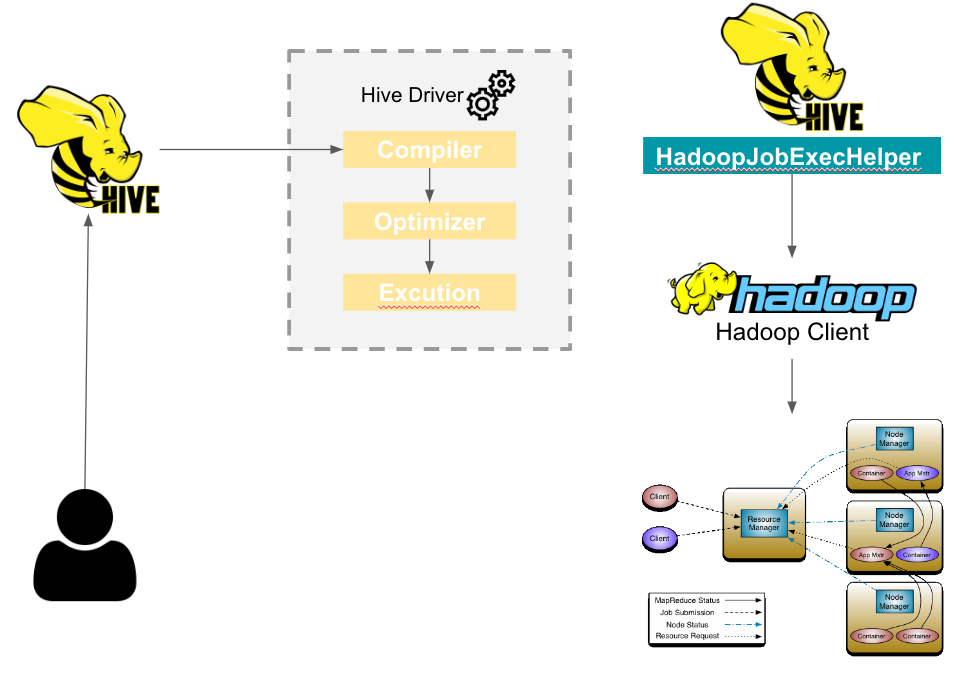
1. Hive에서 M/R 작업을 실행 시키는 과정.
Hive Driver에 Compiler는 Hive Metastore에서 필요한 읽기/쓰기 정보를 사용하여 쿼리를 구문 분석해 실행 계획을 생성.
Driver에 Optimization에 의해 최적화됨.
Excution Engine에서 HadoopJobExecHelper를 호출하여 Hadoop Client로 제출.
Hadoop Client는 제출된 MapReduce 작업을 Yarn Resource Manager에게 전달.
Yarn Resource Manager는 아래 그림과 같이 Application Master를 실행하고 각각의 Application Master는 Node Manager에게 Container 실행 명령을 전달.
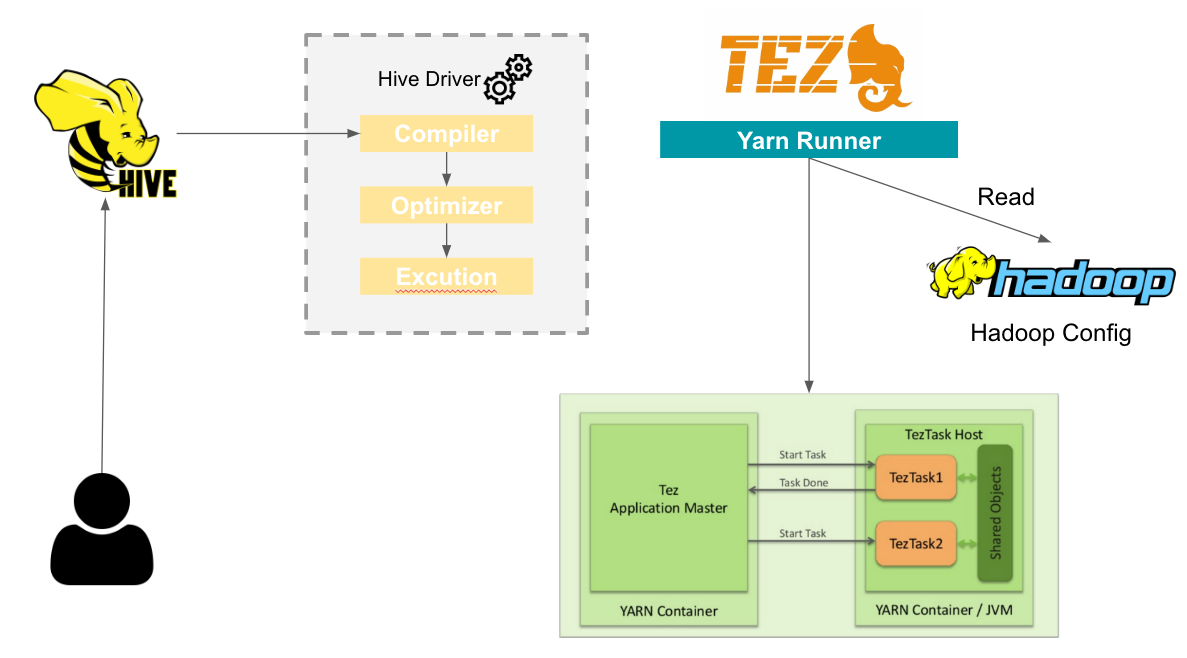
2. Hive에서 Tez 작업을 실행 시키는 과정.
Hive Driver에 Compiler는 Hive Metastore에서 필요한 읽기/쓰기 정보를 사용하여 쿼리를 구문 분석해 실행 계획을 생성.
Driver에 Optimization에 의해 최적화됨.
Excution Engine에서 YARNRunner를 호출하며 YARNRunner는 Hadoop _HOME(환경설정)에 잡힌 Hadoop의 Config를 읽어 Yarn에 작업 제출.
Yarn Resource Manager는 아래 그림과 같이 Tez Application Master를 실행하고 각각의 Application Master는 TezTask에게 Container 실행 명령을 전달.
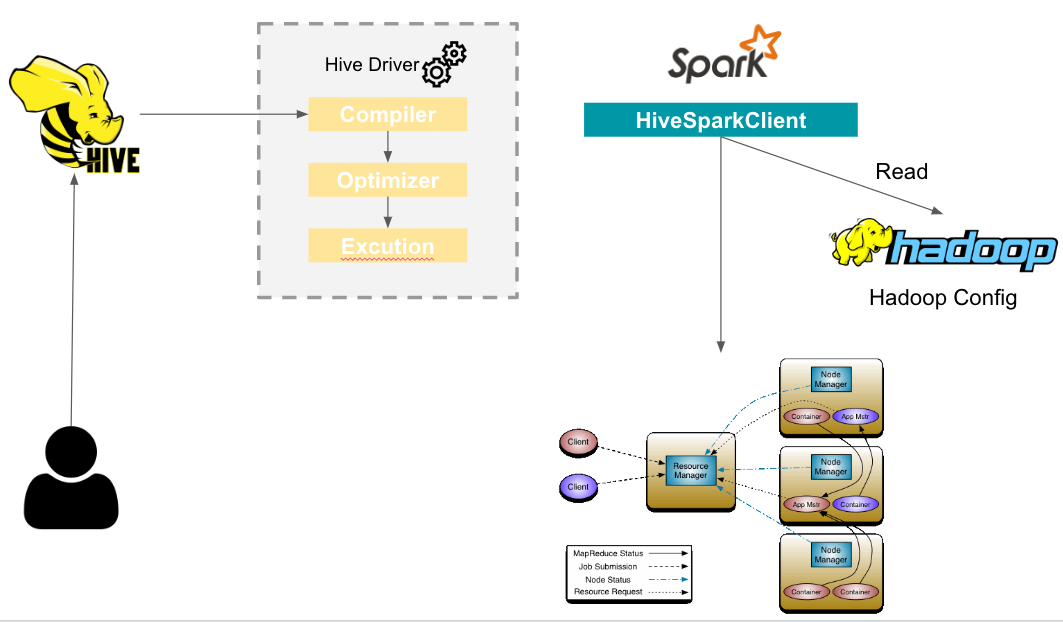
3. Hive에서 Tez 작업을 실행 시키는 과정.
Hive Driver에 Compiler는 Hive Metastore에서 필요한 읽기/쓰기 정보를 사용하여 쿼리를 구문 분석해 실행 계획을 생성.
Driver에 Optimization에 의해 최적화됨.
Excution Engine에서 HiveSparkClient를 실행시켜 Spark Job을 생성하며 Spark Job을 Yarn에 제출.
Yarn Resource Manager는 아래 그림과 같이 Application Master를 실행하고 각각의 Application Master는 Node Manager에게 Container 실행 명령을 전달.
[참고 1] https://tsktech.medium.com/apache-tez-2fd0d6a1d4e3
[참고 2] https://www.analyticsvidhya.com/blog/2020/10/getting-started-with-apache-hive/