MapR 사업성 검토를위해 기존에 사업을 진행하고 있는 Cloudera와 비교 자료를 작성해보았다.
1. 설정 및 설치
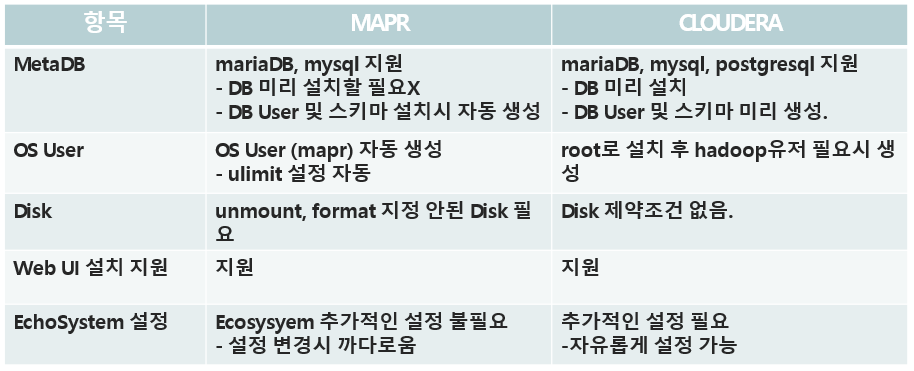
- MAPR 과 CLOUDERA 모두 Web UI 설치를 지원하여 간단하게 설치를 할 수 있습니다.
- MAPR은 자체적인 Filesystem을 사용하기 때문에 unmount된 디스크가 필요하다는 단점이 있습니다.
- MAPR은 Ecosystem의 개별적인 설정이 불필요하여 설치 후 간단하게 사용할 수 있지만 세부 설정이 어려운 단점이 존재하며 -CLOUDERA는 Ecosysyem 개별 설정이 가능한 페이지가 존재하여 Web 에서 설정 가능.
2. 성능
2.1 Sqoop, Hadoop fs –put 성능
- Cloudera 와 MapR은 모두 3개의 노드로 구성되어있고 하드웨어 사양은 아래와 같다.
| 항목 | 사양 |
|---|---|
| CPU | v4core |
| Memory | 16G |
| OS | CentOS 7 |
| Disk | SSD 100G |
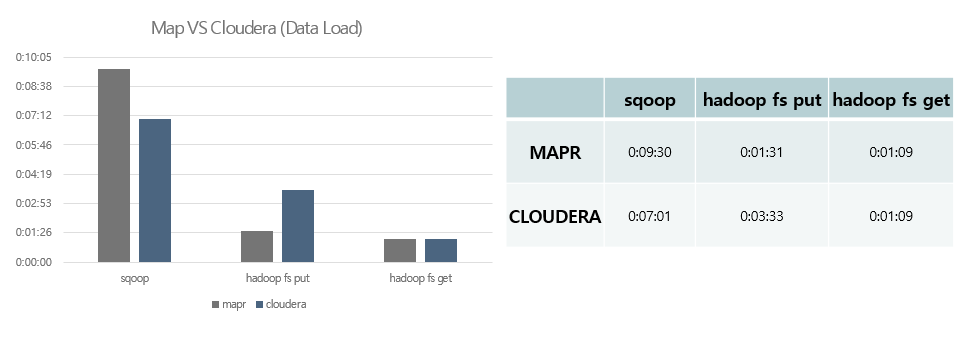
- MAPR은 Hadoop 파일 시스템에 데이터를 올리는 put 명령어는 빠른 성능을 보이지만 데이터를 내려 받는 get 명령어는 비슷, Sqoop은 CLOUDERA가 우세한 성능을 보여줬습니다.
- 테스트에 실행된 Sqoop의 맵 테스크 개수는 8(기본 맵 테스트 개수는 4 –m 8)이며 Direct 모드로 실행했습니다.
- Sqoop 에서 Direct 모드는 Mysql, Postgresql 만 지원합니다.
2.2 SQL 엔진 성능
- 테스트에 사용된 데이터는 약 15G
- Impala에서 Random Access는 MAPR 과 CLOUDERA 모두 비슷한 성능을 내었지만 ranking을 구하는 쿼리에서는 CLOUDERA가 더 높은 성능을 냈습니다.
- Hive에서는 큰차이로 MAPR이 우세했는데 MAPR은 Hive가 Tez엔진으로 돌아가기 때문에 큰 차이가 나는 것으로 보입니다.

3 클라이언트
- MAPR은 Client가있어 Hadoop이 설치되어있지 않은 서버에서 Hadoop 명령어를 통해 hdfs에 파일 업로드 가능합니다. - 15G 약 1억건의 데이터를 옮기는데 약 8분8초가 소요됩니다.
- Cloudera는 SCP로 데이터를 옮긴 후 다시 put 명령어로 Data를 옮겨야 하기 때문에 더 많은 시간이 소요될 것으로 예측됩니다.
- MAPR 은 POSIX 클라이언트도 제공하여 하둡 파일시스템이 필요한 다른 솔루션과 연동이 쉽게 됩니다.
4 Community 활성화
- 커뮤니티 URL을 구글에 검색하면 2,560,000 vs 616,000 건수로 CLOUDERA가 4배 이상 검색이 많이 됩니다. 실제로 MAPR에서 에러가 발생하여 에러메시지를 검색해보면 CLOUDERA 커뮤니티글이 많이 검색됩니다. 하지만, Ecosystem의 에러는 대부분 MAPR에 종속 되어있는 에러가 아니라면 해결이 가능할 것으로 보입니다.
5 기타 사용하면서 느낀점
- CLOUDERA와 다르게 MAPR은 Ecosystem의 계정을 따로 만들지 않고 mapr 계정으로 관리하여 파일 읽기 쓰기 권한을 따로 부여 해야하는 번거로움이 없습니다.