1.Tez와 MapReduce의 동작 차이.
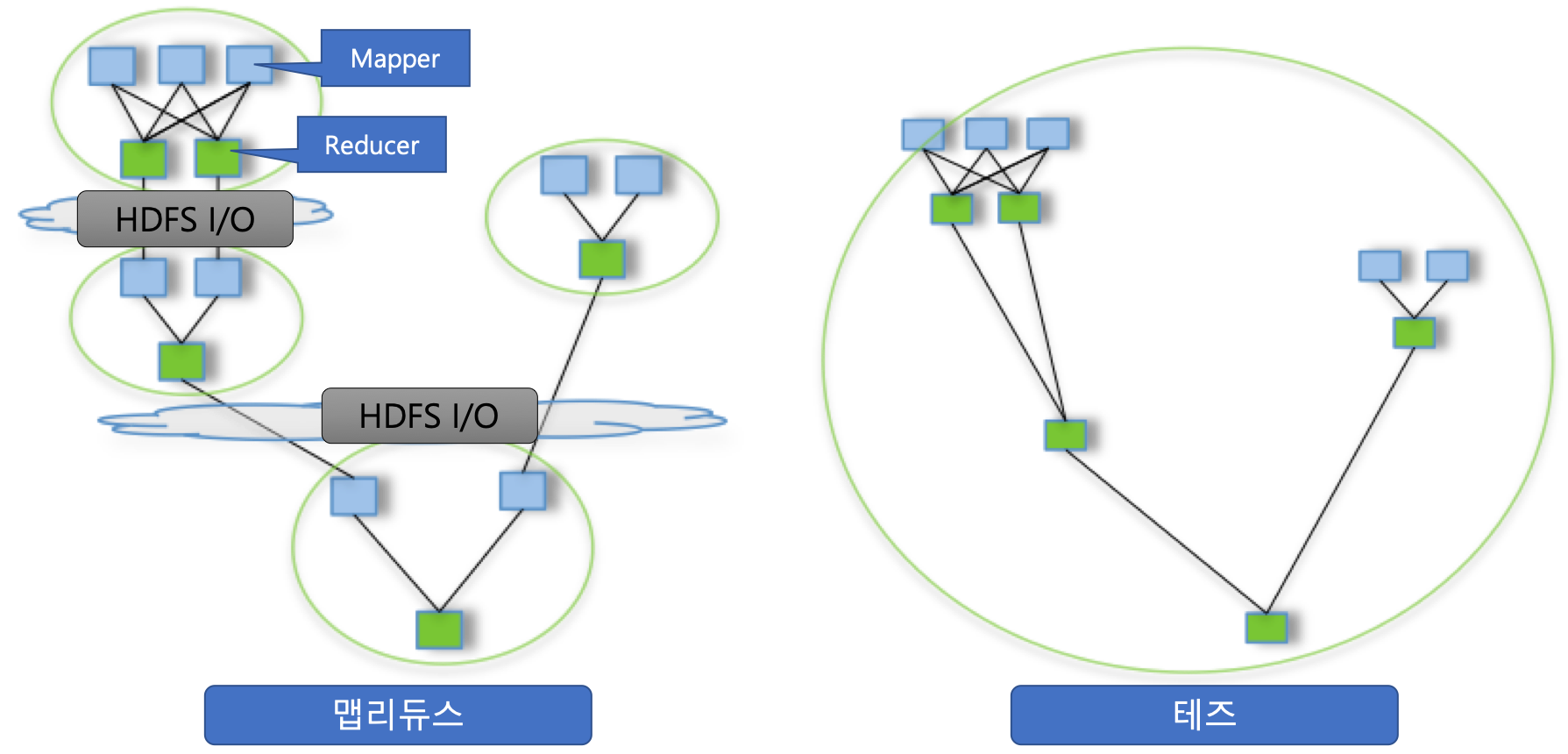
MapReduce는 크게 데이터를 원하는 Key-Value 형태로 만드는 작업인 Map과 Map 작업이 끝난 데이터를 합치는 Reduce 작업으로 나눌 수 있는데 이 Reduce 작업이 끝나고 중간 결과를 HDFS에 저장한 뒤 다시 Map과 Reduce 작업을 반복하는 과정에서 Disk I/O가 발생하게 되어 작업의 속도가 느려진다. 하지만, 테즈(Tez)는 미리 실행계획을 계산하여 DAG(비동기 사이클 그래프)로 작업 순서, 리소스를 최적화하여 Disk에 저장하지 않고 Map단계의 데이터를 메모리에 저장하여 Reduce에 전달함으로써 데이터 작업 처리속도를 증가시켜준다. 하지만, stage(Map과 Reduce가 반복되어 Disk I/O가 발생하는 단계)가 나누어 지지 않는 간단한 작업에 대해서는 처리 속도향상을 기대하기 어렵다.
2. Tez사용 설정.
Hive가 기본적으로 Tez엔진으로 실행되기 위해서는 hive-site.xml에서 아래의 설정을 추가해야한다.
SET hive.execution.engine = tez;
3. Tez 메모리 설정.
인터넷 검색하다 보니 Tez 작업이 메모리 부족현상(Out Of Memory)으로 작업이 실패하는 경우가 있다고 하는데 이 경우 알아 보니 대게 Tez 작업의 Memory 설정에 문제가 있다는것을 알았다.
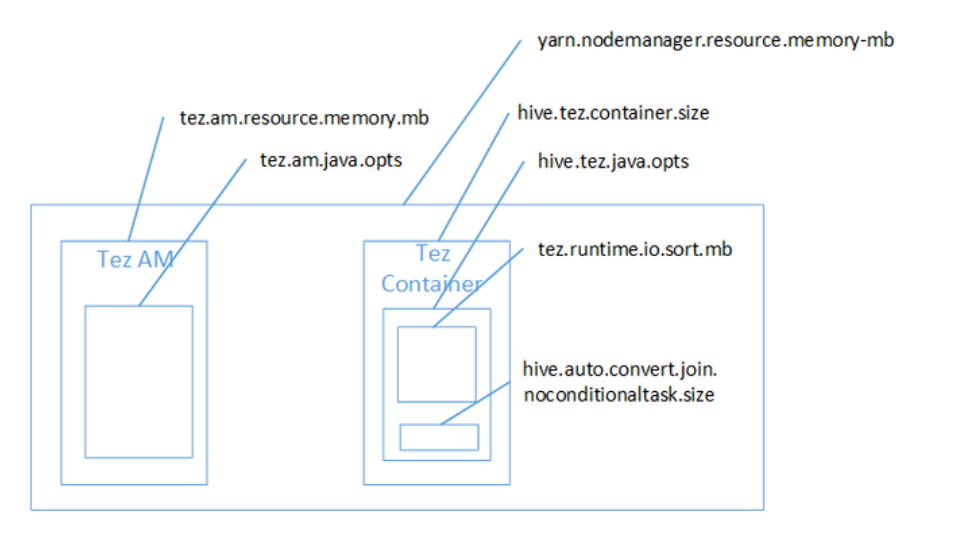
--------------------------- AM(Application Master) 메모리 -----------------------------
// AM(Application Master)의 메모리
set tez.am.resource.memory.mb=2048;
// AM(Application Master)이 사용할 힙메모리 사이즈(tez.am.resource.memory.mb의 80%)
set tez.am.java.opts=-Xmx1600m;
---------------------------------- container 메모리 ----------------------------------
// tez 작업을 진행하는 컨테이너의 메모리 크기
set hive.tez.container.size=2048;
// 컨테이너에서 사용할 수 있는 힙의 메모리 크기
set hive.tez.java.opts=-Xmx1600m; // hive.tez.container.size의 80%
// 출력결과를 정렬해야 할 때 사용하는 메모리
set tez.runtime.io.sort.mb=800; // hive.tez.container.size의 40%
// 맵조인에 사용하는 메모리
set hive.auto.convert.join.noconditionaltask.size=600; // hive.tez.container.size의 33%
Tez 메모리 할당 방식.
출처[1] : https://kr.cloudera.com/products/open-source/apache-hadoop/apache-tez.html
출처[2] : https://118k.tistory.com/399
출처[3]: https://118k.tistory.com/713 [개발자로 살아남기]